

摘要:【目的】探讨人工智能生成内容(AIGC)技术在辅助图书插图、期刊封面设计以及期刊论文短视频创作中的应用场景,提出生成式人工智能(GenAI)赋能学术期刊融合出版与传播的新途径。【方法】通过厘清四类 AIGC 模态(文本、图像、声音、视频)的概念,增强对 AIGC 具体技术与应用的认知。从语言的温度、普通提问、结构化提问、提示工程四方面阐述如何与 ChatGPT 等AI 实现高效率沟通。以 AI 辅助插图与期刊封面设计、虚拟数字人视频的创作为例,分析 AIGC 技术在期刊出版与传播中的应用。【结果 / 结论】AIGC 技术提高了期刊内容的视频生产效率,使复杂的学术论文能够快速转化为短视频形式,增强了信息的可视化效果和传播的灵活性。AIGC 技术在学术期刊的融合出版与传播中的应用具有很强的可行性,能够有效推动知识传播的创新与变革。
关键词:AIGC 技术;期刊论文;短视频;内容创作;知识传播
DOI:10.19483/j.cnki.11-4653/n.2025.01.002
本文著录格式:谭春林,郑宇云,王建平,徐志武 . 生成式人工智能赋能学术期刊融合出版与传播[J]. 中国传媒科技,2025,32(1):12-17.
基金项目:广东省科技计划“高水平科技期刊建设项目”“《华南师范大学学报(自然科学版)》高质量科技期刊建设”项目(项目编号:2024B1212100006);广东省科技计划项目科技期刊办刊人才项目“基于‘国际施引指数’新模型的科技期刊国际影响力提升策略研究”(项目编号:2024B1212110009);中国科学技术期刊编辑学会项目“科技期刊论文的视频化出版、科学数据的增强出版”(项目编号:CESSP—2023—C06);中国高校科技期刊研究会项目“善锋软件基金”(项目编号:CUJS2023—SF004)。
作者简介:谭春林(1978—),男,湖北恩施,博士,副编审,华南师范大学教育信息技术学院出版专业硕士生导师,研究方向为期刊编辑与出版、新媒体融合与传播、AIGC应用边界与伦理。郑宇云(1983—),男,广东湛江,华南师范大学期刊管理中心副主任,研究方向为期刊管理、融媒体。王建平(1969—),男,华南师范大学期刊管理中心主任、主编,研究方向为期刊管理、教育学。徐志武(1990—),男,安徽太湖,副教授,硕士生导师,华南师范大学教育信息技术学院特聘副研究员,研究方向为出版经营管理、数字教育出版与传播、港澳青年与内地媒介。
在信息爆炸的时代,传统的学术期刊在传播知识时面临效率和读者体验上的双重挑战。学术论文往往篇幅冗长,语言专业性强,许多非专业读者难以在短时间内获取其中的关键信息。同时,随着短视频平台的兴起,越来越多的用户习惯于通过简短、生动的多媒体内容获取知识。如何将复杂的学术知识转化为易于理解的短视频,并以更加灵活和互动的方式传播,成为期刊出版行业的重要课题。
在新媒体时代,人们的阅读习惯发生了巨大变化,已经习惯利用碎片化时间获取信息和知识。学术论文因篇幅过长、语言难懂、阅读时空受限等原因,不易通过移动新媒体传播。通过 “解码” “降维”的期刊论文短视频编码策略 [1],将晦涩难懂的学术论文转化为符合视听规则及用户喜好的短视频,适宜在移动端快速传播,从而实现由短视频的“浅阅读”引流“深阅读”,加速论文传播,扩大期刊的影响力。
人工智能生成内容(AI-Generated Content,AIGC)是与专业生成内容(Professionally Generated Content,PGC)、用户生成内容(User-generated Content,UGC)相互区别的一种新型的内容生产方式。AIGC 技术是人工智能在内容生成领域中的重要应用。在学术出版与传播研究领域,目前主要开展 AI 文本检测 [2-3]、场景运用 [4-7]、权益保护 [8-9]、伦理治理 [10-11] 等方面的研究。AIGC技术以其高效率、高质量、高效能的优势成为内容产业的新质生产力。AIGC技术的兴起为内容创作与二次生产提供了有效的解决方案。本文在前期研究[12-13]的基础上,从 AIGC技术的多模态分类、应用案例以及优势与挑战等方面,系统分析 AIGC技术在期刊论文短视频创作与传播中的赋能作用。
NO.1
AIGC 技术概述
2022年12月,ChatGPT的横空出世,掀起了全球生成式人工智能(Generative Artificial Intelligence,GenAI)的研究浪潮,标志着人工智能从AI1.0进入了AI2.0,也标志着生成式人工智能时代(GenAI Era)的到来。以ChatGPT大语言模型(Large Language Models,LLM)为领头羊,掀起了全球生成式人工智能的爆发式发展。大语言模型的典型代表包括:OpenAI 的ChatGPT、微软的NewBing、Google的Bard/Gemini、Anthropic的Claude、深度求索的DeepSeek、月之暗面的Kimi、讯飞的星火、清华的智谱清言、百度的文心一言、阿里的通义千问、腾讯的混元、华为的盘古等。随着时间的推移,人工智能将有可能实现通过不同的感官模式(视觉、听觉、触觉甚至嗅觉)来传达信息和进行交流交互,而目前的AIGC技术能处理文本、图像、声音、视频等多模态数据,该技术通过先进的算法和模型,极大地丰富了内容的创作和呈现方式,提高了内容创作的效率,降低了创作成本,为内容生产行业带来了革命性的变化,也为期刊短视频创作与传播赋能。
1.1 文本模态
生成式预训练变换器(Generative Pre-Trained Transformer,GPT)是基于Transformer架构的大型语言模型(Large Language Model,LLM),是一种基于深度学习(Deep Learning,DL)的自然语言处理(Natural Language Processing,NLP)技术,能够根据先前的输入来生成自然语言文本,通过自回归(Autoregressive)方式从文本到文本(Text-To-Text)生成内容。与具体执行某一功能(例如下围棋、机器翻译等)的小模型不同,GPT 兼具“大模型”和“预训练”两种属性,通过在海量通用数据集上进行预训练,来实现AI的泛化性、通用性和实用性。典型的代表有:ChatGPT、Gemini、Claude、Kimi、DeepSeek等,其中DeepSeek在开源大模型的主流榜单中位列榜首 , 与世界上最先进的闭源模型不分伯仲。
1.2 图像模态
图像模态主要包括图像识别和文生图(Text-To-Image Generator)两大类。图像识别(Image Recognition)是指软件具有分辨图片中的人物、位置、物体、动作以及笔迹的能力,属于机器视觉的范畴,它利用软件对图像进行处理、分析和理解,以识别各种不同模式的目标和对象,例如:文字识别、数字图像处理与识别、物体识别。文生图则是通过文本描述生成图像的技术。与图像描述(Image Captioning,IC)的研究相比,文生图的研究图像所包含的信息更为复杂,因此文生图任务的提出晚于图像描述。2016年Scott等首次提出了能根据文字生成图片的生成式对抗网络(Generative Adversarial Networks,GAN),实现从文字到逼真图像的转化。该任务包含两部分:(1)利用自然语言处理来“理解”输入的文本描述;(2)生成网络输出一个准确、自然的图像,对文字进行可视化表达。人工神经网络(Artificial Neural Network,ANN)产生的图像接近真实图像,为解决文本生成图像的问题找到了解决思路。典型代表是David创办的 Midjourney、OpenAI的DALL-E、Google的Parti、Stability AI 的Stable Diffusion、FluxAI的Flux等。
1.3 声音模态
声音模态基于深度学习技术,通过对大量语音数据进行训练,实现了对语音的高效识别和理解。这一技术的出现,让机器与人类的沟通变得更加自然、流畅。声音模态包括:文本转语音(Text-To- Speech,TTS)、语音转文字(Speech-To-Text,STT)、文本生音乐(Text-To-Music,TTM)。前两种功能基于自然语言处理和语音识别与合成技术,既可以将文字转化为自然流畅、富有情感的语音,又可以“听懂”人类语言,成为人机交互的关键技术。TTS 的典型代表有:WaveNet、FastSpeech、MFA和ChatTTS 等,其中ChatTTS的特点是合成的语音接近普通大众的口音风格,适合做普通生活类的短视频。另外,多数虚拟数字人合成软件或网站平台,也提供了大量语音效果逼真且达到播音水准的主播语言风格。TTM 的典型代表是Melodio、Mureka、Suno、Udio、天工SkyMusic等,其中Suno和SkyMusic不仅能作曲,还能生成高质量的模拟人声歌唱的歌曲。
1.4 视频模态
视频模态技术依托深度学习模型对多种输入数据(如文本、图像或现有视频)进行深刻理解与处理,进而生成动态且连贯的视频序列。该技术的核心在于整合自然语言处理(NLP)与计算机视觉(CV)领域的最新进展,使得机器能够更加精准地解读人类指令,并将其转化为富有表现力的视觉内容。视频模态的功能包括:文本生成视频(Text-To-Video,TTV)、图像生成视频(Image-To-Video,ITV)以及视频生成文本(Video-To-Text,VTT)。TTV能够根据用户提供的文字描述自动生成相应的视频内容;ITV则基于单张或多张图片,生成动态的视频序列,模拟图像中场景的变化或动作的演进;VTT 则能够从视频中提取信息(如图像、音乐、人声、字幕等),生成相应的文本描述(或台词),便于内容的索引、检索与理解。典型的代表是OpenAI的 Sora、Google的VideoPoet以及由Morph和Stability AI合作推出的Morph Studio。Sora能够根据复杂的文本描述生成高分辨率的视频内容,而VideoPoet则擅长将诗歌等文学作品转化为富有艺术性的动态影像。国内视频AI的典型代表是字节跳动的即梦AI、快手的可灵AI,另外不少AI软件平台(例如剪映软件、腾讯智影数字人网站等)也集成了文生图、垫图生图(做同款)、智能画布(简笔作图)等功能。
NO.2
如何与ChatGPT等AI高效率沟通
以ChatGPT为代表的大型语言模型,其“思维模式”与人类存在显著差异。因此,如何与 AI 高效沟通成为获取优质回复内容的关键。提示(Prompt)的质量直接影响AIGC的质量。与AI高效率沟通的策略:(1)给GPT一个明确的提示。清晰地告诉GPT我们需要什么。如果我们提出的需求不明确,GPT只能“猜测”我们的目的,而减少模型的“猜测”,有助于得到更满意的结果。(2)向 GPT提供阅读材料(背景知识)。让GPT“空想”一个话题(特别是冷门话题)时,它往往表现为“信口开河”,如果给足背景知识,GPT的回复更为靠谱。(3)把复杂的任务拆解为简单的子任务。将大任务拆解成一连串的小任务(工作流),GPT更容易完成,且准确率较高。例如先让GPT写提纲,再针对提纲中的每一条标题逐一提问,最后将所有小任务的内容汇总后,让GPT整理成篇。
2.1 语言的温度
语义表达中的语言是有温度的,可以表达不同的情感或语气,GPT4等AIGC模型都可以由提问者提出个性化的语言温度风格,用于不同的受众对象和应用场合。相同内容的提问可以通过在 Prompt提示语末尾添加语言的温度指令 [14],得到不同风格和语气的内容。
温度指令:
please generate an answer at X.
或 Use a temperature of X,
其中,X=0.1 ~ 1。低温生成的文字表述稳重严谨,适合学术写作;而高温生成的文字充满创意和想象力,适合儿童文学创作。另外,可以通过调节语言温度,将晦涩难懂的学术论文摘要改写为短视频文案和剧本,增强论文短视频的大众可接受性。
2.2 普通提问
在普通的日常查询类提问应用中,不用太在意所谓的提示结构或提示工程,与平常人与人之间的交流一样,通常能够让GPT快速理解并准确回应。例如:请解释一下量子力学的基本概念,并举一个实际应用的例子。再如:我想了解如何提高科技论文稿件的编辑与校对工作效率,能否提供一些实用的技巧?这种普通提示强调了问题的具体性和清晰性,使得AI能够更准确地理解用户的需求,从而生成相关且有价值的内容。
在创意生成场景中,用户可以采用开放性的问题,鼓励AI进行更具创造性的回应。例如:请为我构思一个关于时间旅行的短篇小说大纲,包含主要角色和情节发展。再如:我想要一个关于环保主题的广告创意,能否给我一些灵感?这种普通提示允许AI在更广泛的范围内进行思考,激发其创造力,从而生成更具创新性和多样性的内容。
2.3 结构化提问
在文本写作方面,利用简单的一个标题或一句话向GPT提问,通常会得到一种语言表达和逻辑结构完美但是凭空创造的空洞且泛化的“无中生有”的内容。为了获得高质量的回复内容,需要在提问的提示语中包含身份扮演、背景知识、任务安排以及具体要求等信息,同时注意提问的逻辑性,而提示语的结构化会厘清提问内容的逻辑,增强 AI 对提示文本的“理解”。提问结构 [14]:交代背景、赋予身份、分配任务、提出要求。
2.4 CO-STAR提示工程
在更具系统性的策划或报告创作方面,提问者如果提供足够的信息,往往可以得到高质量的内容。提示语信息量的增大,也增加了 AI 的“理解”难度,此时一个好的提示框架、提示工程是决定生成内容质量优劣的关键。2023年11月8日,新加坡举办了首届 GPT-4提示工程(Prompt Engineering)竞赛。数据科学家 TEO Sheila夺冠成为“提示女王(PromptQueen)”。随后,TEO Sheila发布了一篇题为“我如何赢得了新加坡GPT-4提示工程赛”的博客文章,提出了CO-STAR提示工程(图1)
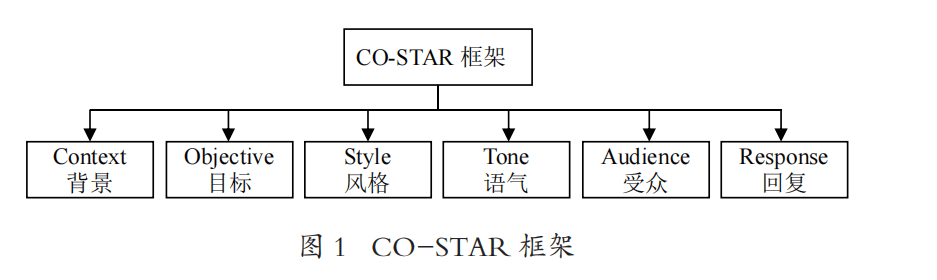
基于CO-STAR框架,我们可以给出两个结构化提示语案例,获得比简单的普通提问指令生成内容质量更高的内容。限于篇幅,以下仅展示提示语而不展示生成内容。
以“#”等类似于Markdown语法格式的分隔符为例:
# Context #
我想为编辑部拟定一则英文的征稿启事。我们的刊名是Carbon Research,征稿主题为“大规模地下空间能源利用和储集理论与技术”,这是“碳捕集、封存、利用和转化”(即CCUS)的一个子课题。
# OBJECTIVE #
为我创建一则英文的征稿启事,旨在吸引研究者关注本刊、向本刊推荐优秀稿件。
# STYLE #
遵循优秀同类英文科技期刊的写作风格。
# TONE #
具有说服力
# AUDIENCE #
我公司在Facebook上的受众通常是老年人。请根据这一受众的需求定制你的帖子,关注他们在护发产品中通常看重的特点。
# RESPONSE #
这条Facebook帖子应简洁而有影响力。
如果任务很简单,则分隔符对GPT4的回复内容质量影响不大,例如前面的普通提问。然而,任务越复杂,使用分隔符进行分节对GPT4的回复内容质量的影响就越明显。
用特殊字符当分隔符,分隔符可以使用任何通常不会同时出现的特殊字符序列(如 ###、===、>>> 等)。特殊字符的数量和类型并不重要,只要它们足够独特,以便GPT4将其理解为内容分隔符,而不是普通的标点符号。
以“<<<”等特殊分隔符为例:
对 <<< 对话 >>> 中每个对话的情感进行分类,标记为“积极”或“消极”。请仅给出情感分类,不要添加任何其他前置引导文本。
示例对话
[ 客服 ]:早上好,我今天可以为您提供什么帮助?
[ 客户 ]:这个产品太糟糕了,和广告上说的完全不一样!
[ 客户 ]:我非常失望,期待全额退款。
[ 客服 ]:早上好,我今天可以为您提供什么帮助?
[ 客户 ]:你好,我只想说我对你们的产品真的很满意。它超出了我的期望!
示例输出
消极
积极
<<<(对话内容略)>>>
NO.3
AIGC 技术在期刊出版与传播中的应用案例
新媒体技术的迅速发展为传统科技期刊的出版、传播带来新的机遇和挑战。传统科技期刊的订阅渠道为“被动传播”,导致中文科技期刊的影响力弱。利用公众号、视频号与微信群协同推动学术期刊的“主动传播”[15]。利用AIGC技术根据论文摘要与研究亮点等内容制做出虚拟数字人播报视频 [16],可以实现学术论文的增强视频出版、促进期刊论文的传播、扩大期刊品牌宣传。AI短视频的创作过程往往涉及文生文、文生图、文生语音、文生视频、图生数字人等AIGC技术。
3.1 用DALL-E3辅助插图与期刊封面设计
利用DALL-E3、Stable Diffusion、Midjourney、Flux、通义万象、腾讯智影等模型可以实现“文生图”。已有少数期刊开始尝试利用这一技术设计期刊的封面,例如《现代纺织技术》《内蒙古电力技术》《南方能源建设》等期刊。笔者对文生图做了大量的尝试,应用于图书插图、期刊封面、漫画书插画、短视频场景等方面(参阅“三叶学术”视频号)。利用AIGC辅助插图与封面设计具有很强的可行性,既提升设计效率,又降低设计成本。
与Midjourney模型一样,DALL-E3和Stable Diffusion均需采用英文提示,通常可以采用文本模型(如GPT4)充当绘图模型的提示工程设计师,设计绘图思路并提供英文的绘图提示语,例如 https://ai-sci.top平台自动对接文本模型和绘图模型,集自然语言处理、提示工程设计、绘图模型调用等功能于一体。而对于直接使用绘图模型的用户而言,AI绘图的提示指令不需要像提示工程的句式一样完整和复杂,只需要用逗号分隔、按主次先后列出关键词。可通过添加括号设置主体的权重来强化主角,也可以通过设置负向提示词避免图中出现某些对象。
采用提示词而非提示语(或提示工程)具有两个好处:一方面可以降低AI绘图模型用来“理解”自然语言所需的算力;另一方面可以给予AI模型足够的“想象”和“创作”空间,使生成的绘图更好。对于相同的创意内容,如果添加一些专业的绘图提示词,就能绘出不同风格的图。表1是66种不同绘图风格的提示词,例如电影级别(35mm-film)、广角(wide-angle)、动漫(anime)等。
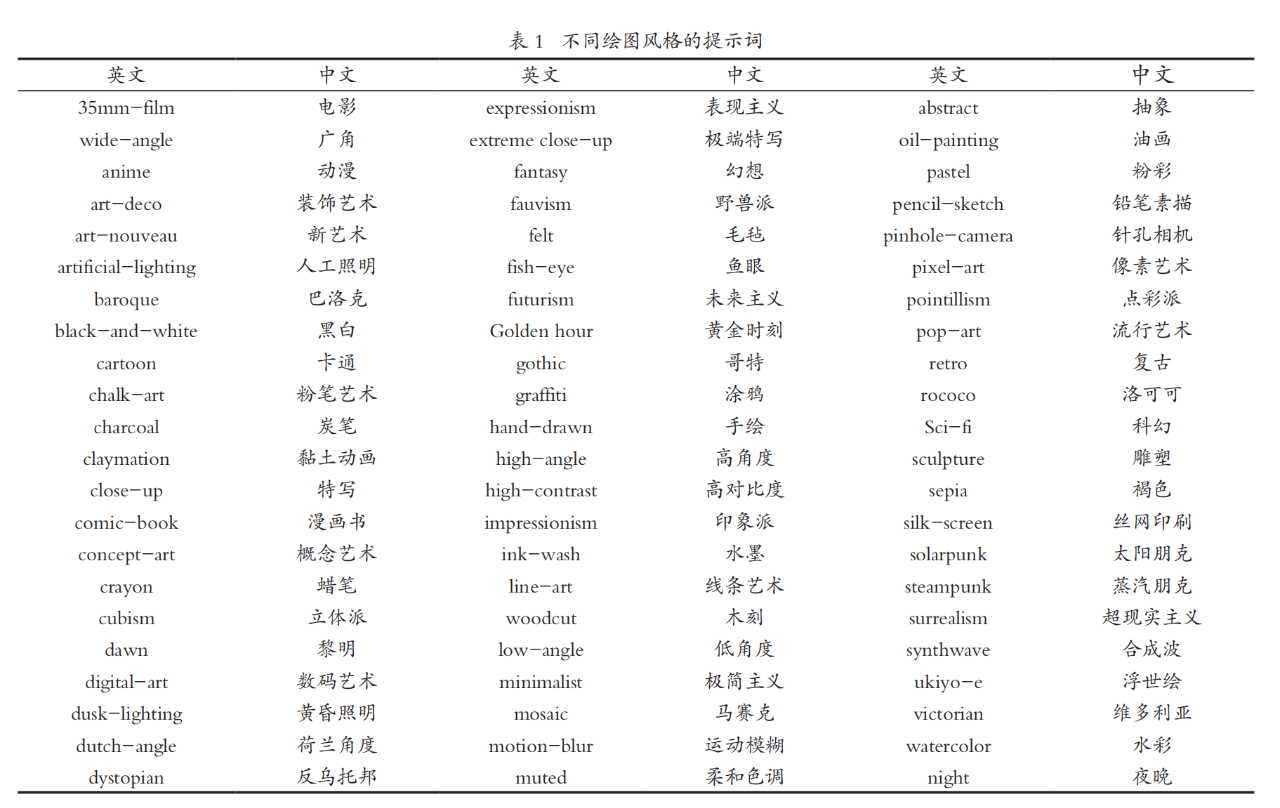
图2是DALL-E3、Flux和Stable Diffusion的绘图效果。图2(a)~(d)采用DALL-E3模型绘制,其中图2(a)~(c)是相同的创意经过微调后得到的效果图。图2(a)的提示语:生成油气田场景图,画面简单,构图精美,远景。图2(b)和图2(c)的提示语分别在图2(a)的提示语基础上增加“生成摄影作品”“生成相片”。这三张图片所表达的语义是相同的,仅画面风格不同。但需要注意的是,采用 DALL-E3 等绘图模型绘图时往往会出现很多荒谬和错误。例如图2(d)为采用一篇论文的摘要生成的图,图中文字出现乱码。再如AI在人物特写中对手指的认知尚存缺陷,通常会出现多个手指。因此,在使用前需审图,利用各类AI工具局部重绘消除图中差错。以图2(d)为底图可设计出期刊封面 [ 图 2(e)],该封面也可作为竖屏短视频的封面,在短视频的传播中扩大对期刊的品牌宣传。

Flux和Stable Diffusion 模型的绘图能力也表现不俗。图2(f)的提示语:中国画,中国工笔画的青山技法,笔法雄浑有力。掩映在青山之间的是一个乡村气息浓厚的小村庄。远处的群山绵延无边,顶端绿草如茵,美不胜收。透过画面感受大自然的活力,具有东方内涵的景色相互映照。让人心旷神怡,流连忘返。图2(g)为采用 Stable Diffusion 绘制的绘本插画,提示语:A cute rabbit is planting flowers in a forest,comic-book。
3.2 AI辅助虚拟数字人视频的创作
以《人民珠江》视频号发布的论文视频摘要为例,解析虚拟数字人视频的创作过程。在创作科技论文虚拟数字人播报视频之前,需准备:论文作者提供的实验小视频、论文亮点演示文稿(设置播放动画)、腾讯智影数字人制作网站、录屏软件、剪辑软件。腾讯智 影(https://zenvideo.qq.com)网站集成了10余种AIGC模型,是功能较全面的AIGC平台。例如:文本配音、动态漫画、智能抹除、文章转视频、数字人播报、字幕识别、智能抠像、数字人直播、智能转比例、AI绘画、图像擦除、视频解说、视频审阅、智能画布等。虚拟数字人的合成涉及文生文(改写文案)、文生图(定制主播形象)、文生语音(播报语音)、图生视频(让主播做动作)、文生音乐(创作背景音乐)等AIGC技术,合成方法可参考文献[15]。具体步骤:采用文本模型(例如GPT4、Kimi 等)设计短视频脚本、剧本和分镜。根据GPT设计的分镜画面描述文本,利用即梦AI(或可灵AI)以及智影数字人、剪映等软件的“文生图”功能生成画面,再利用即梦 AI 的“图生视频”功能将每张画面生成“具象化”“可视化”“动态化”为视频片段,最后利用剪映软件将旁白(字幕)、旁白配音、视频片段等AIGC素材剪辑合成科普短视频,增强学术论文的易读性、传播力。
3.2.1 用AI改写科普化摘要
通过难度降维、亮点拆解的方式,利用DeepSeek、Kimi、文心一言、豆包等 AI 模型将论文改写为通俗易懂的科普短文,根据期刊新媒体的受众定位和用户画像特征,修改语言温度与风格,生成用户个性化阅读需求的公众号文章、短视频、学术文创等。
3.2.2 用AI设计主播形象和插图
选择腾讯智影网站的“AI 绘画”功能,可在“画面描述”中输入:中国科技新闻的主持人。单击“生成绘画”,可生成4张不同长相和着装的主播照片。如果采用GPT4作为英文提示词助手调用DALL-E3、Midjourney、Stable Diffusion等绘图模型,将默认生成外国人面孔和渐变背景 [ 图3(a)],需在提示词中补充国别和背景色限定词,或采用智影、即梦、可灵等AI的“图生图”功能,通过输入 “换为中国人面孔,背景改为绿幕”相关的提示语,实现面孔更换和绿幕背景设置的任务 [ 图 3(b)]。

3.2.3 虚拟数字人视频合成
期刊论文的视频摘要往往需要呈现重要的图表数据和亮点结论,常用的方法是利用录屏软件录制PowerPoint的演示动画。对于背景动画的创作,可以采用即梦AI(或可灵AI)将静态的绘图转化为动画视频片段,例如提示让图3(b)中的主播举起手中的杂志。对于短视频所需背景音乐、片头曲、片尾曲的创作,可以利用Suno音乐AI模型创作。对于口播数字人视频的合成,可以利用腾讯智影网站将AI生成的主播形象图片上传到的“数字人播报”模块,输入文案台词,选择合适的语音包,通过试听检查不存在错读、多音字、连读、停顿等问题之后,单击“合成视频”按钮即可生成虚拟数字人视频,视频封面截图如图3(c)所示。
NO.4
AIGC技术面临的挑战
尽管AIGC技术在内容创作方面展现出了巨大潜力,但在学术期刊的应用中仍面临一些挑战:(1)内容准确性。由于AIGC技术在生成内容时依赖算法和数据集,因此如何保证其生成内容的准确性仍是一个重要问题。(2)版权与道德问题。AIGC技术在内容生成过程中可能涉及现有的知识产权保护问题,如何在生成内容时遵守版权规定是应用中的另一个挑战。(3)技术与人工的平衡。尽管AIGC技术能够自动生成大量内容,但在高质量的学术创作中,如何平衡人工编辑与AI生成的关系,确保内容的深度和严谨性,是学术期刊编辑者必须面对的问题。
结语
AIGC技术作为一种前沿的内容生成技术,正在为期刊论文的创作与传播带来深刻变革。通过将学术内容转化为形式丰富、易于传播的短视频,AIGC技术不仅能提升知识传播的效率,还能拓宽期刊内容的受众范围。然而,AIGC技术在实际应用中仍面临内容准确性、版权问题等挑战。随着技术的进一步发展与应用,AIGC技术在学术出版中的潜力将更加显著,有望引领期刊内容生产与传播的新潮流。
参考文献:
[1] 邓履翔,沈辉戈 . 编码理论视角下学术期刊短视频编码策略研究 [J]. 中国科技期刊研究,2023,34(3):304-314.
[2] 沈锡宾,王立磊,刘红霞 . 人工智能生成内容时代学术期刊出版的机遇与挑战[J]. 数字出版研究,2023,2(2):27-33.
[3] 薛德军,孔祥煜,耿崇,等 . 人工智能生成中文学术论文文本检测研究[J]. 北京电子科技学院学报,2024,32(3):104-112.
[4] 李侗桐,高瑞婧,田佳 .ChatGPT在中文科技期刊摘要文字编辑中的实用性测试与分析[J]. 中国科技期刊研究,2023,34(8):1014-1019.
[5] 李彦京 . 学术期刊高质量发展中生成式人工智能的运用[J]. 出版广角,2023(12):77-80.
[6] 杨雅 . 生成式人工智能在科技期刊出版中的应用场景探讨[J]. 新闻研究导刊,2024,15(2):242-245.
[7] 丁懿楠,吕冬娟,王先第 .ChatGPT生成内容的权利保护研究[J]. 传媒,2023(24):94-96.
[8] 皮卫东 . AI+ 编辑:人机合作模式探讨[J]. 中国传媒科技,2024(9):92-95.
[9] 沙晓岑 . 生成式人工智能在期刊出版内容生产过程中的侵权责任研究[J]. 北京印刷学院学报,2024,32(2):1-5.
[10] 陈丽 .ChatGPT介入学术出版的伦理研究:赋能与失范[J]. 新媒体研究,2024,10(14):1-6;60.
[11] 郭壬癸 . 使用生成式人工智能对学术出版伦理的冲击与法律治理[J]. 科技与出版,2024(9):25-33.
[12] 谭春林,王建平 . AIGC在学术研究和出版中的使用边界、透明度与伦理[J]. 编辑学报,2024,36(6):661-666.
[13] 谭春林,王维朗,徐志武 , 等 . 生成式人工智能赋能科技期刊论文视频摘要的实践与挑战[J]. 中国科技期刊研究,2024,35(12):1767-1773.
[14] 木白 . AI短视频制作一本通:文本生成视频 + 图片生成视频 + 视频生成视频[M]. 北京:北京大学出版社,2023.
[15] 谭春林 . 公众号、视频号与微信群协同推动学术期刊的“主动传播”[J]. 编辑学报,2021,33(5):549-552.
[16] 谭春林 . 虚拟数字人用于学术期刊视频融合出版实践[J].编辑学报,2023,35(1):89-93.